7.4 More Model Metrics: Sensitivity, Specificity, Precision, Balanced Accuracy, and F1 Score
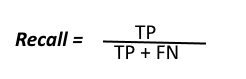
Sensitivity, a.k.a. Recall
A model’s sensitivity can be found by answering the question, “Of all the times when the true outcome class was ‘Positive’, how often did the model accurately predict that outcome?”
| actual renew | actual non-renew | TOTAL | |
| predict renew | 541 | 59 | 600 |
| predict non-renew | 38 | 112 | 150 |
| TOTAL | 579 | 171 | 750 |
When determining sensitivity, we only concern ourselves with the 579 records whose true outcome class was “renew.”
From among that group of 579 records, this model correctly identified 541 of them as predicted renewers. Therefore, this model’s sensitivity rate is 541/579, or 93.44%.
Sensitivity is sometimes described as “recall.” As if two redundant terms were not enough, there is another way to express sensitivity, too – it is sometimes referred to as the “true positive rate.”
Specificity
A model’s specificity can be found by answering the question, “Of all the times when the true outcome class was ‘Negative’, how often did the model accurately predict that outcome?”

| actual renew | actual non-renew | TOTAL | |
| predict renew | 541 | 59 | 600 |
| predict non-renew | 38 | 112 | 150 |
| TOTAL | 579 | 171 | 750 |
Specificity is sometimes referred to as the “true negative rate.”
To measure specificity, we start by limiting our area of focus to only the 171 records whose true outcome class was “non-renew.” Since this model accurately predicted the outcome of 112 records from that group, its specificity is 112/171, or 65.50%.
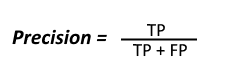
Precision
A model’s precision can be found by answering the question, “Of all the times when the model predicted that a record would belong to the ‘Positive’ outcome class, how often was it correct?” The objective is to minimize the mistakes in guessing positive labels. Note that negative labels are excluded from this metric.
| actual renew | actual non-renew | TOTAL | |
| predict renew | 541 | 59 | 600 |
| predict non-renew | 38 | 112 | 150 |
| TOTAL | 579 | 171 | 750 |
This model predicted a total of 600 renewals; of those 600 records, 541 actually did renew. Therefore, this model’s precision is 541/600, or 90.17%.
A modeler might be especially interested in precision when false positives are very costly.
In the case of spam email filtering, with “Is Spam” as the positive class, and “Is Not Spam” as the negative class, most people would agree that false positives are far worse than false negatives.
In such a scenario, a false negative has a low cost – it’s a momentary intrusion into a person’s workday when he or she receives an email from a prince who has been separated from some great fortune, and needs your help to retrieve it. However, a false positive in such an instance has a high cost – when a legitimate email hits someone’s spam folder, it may lead the sender to think that he or she is being willingly ignored by the recipient.
Balanced Accuracy
The accuracy rate assumes the correct predictions and prediction errors are equally important, but balanced accuracy takes a more nuanced approach – it only cares about the True Positives and True Negatives. In fact, balanced accuracy is the average number of True Positives (Recall) and True Negatives (Specificity).

Balanced accuracy is the go-to metric in instances where there is an imbalance in classes e.g. fraud in credit card transactions. Since the number of non-fraudulent credit card transactions clearly outnumber the dubious ones, we should turn to ‘balanced accuracy’ to assess our model’s effectiveness. For the example above, the model’s balanced accuracy is: (93.44% + 65.50%) / 2 = 79.47%. The closer the balanced accuracy score is to 1, the better the model is able to correctly classify observations.
Note that there are other ways in which balanced accuracy can be measured. It can be weighted by the relative presence of each outcome class in the data, for instance.
F1 Score, and the Inherent Tension Between Precision & Recall
The model’s F1 score combines precision and recall into a single metric by taking their harmonic mean, and is particularly useful when comparing models. If Model A has a high precision score but Model B has a high recall score, then we would compare the performance of both models by referring to their F1 score.

For our example above, the F1 score is: 2 * .9017 * .9344 / (.9017 + .9344) = .9178.
The F1 score metric captures the inherent tension that exists between precision and recall. When a model is adjusted so that false positives become rarer, that makes it less likely to identify any record as belonging to the positive outcome class. This brings precision higher, but it generally brings recall lower.
To think about why, let’s revisit the spam email example. Suppose I tell Microsoft Outlook that I really do not mind receiving the occasional ticket from a lottery winner stranded on a deserted island, but I really dislike it when legitimate emails hit my Spam folder. Accordingly, they adjust the threshold higher for the messages that they will label as “Spam”, making it harder for any message to be labeled this way by the inbox filter. Having fewer messages labeled as spam makes it more likely that actual spam messages will not be identified as such – and that will bring recall down.
Conversely, using a lower threshold for spam email identification means that more messages will be labeled this way. This will make precision lower, since the denominator in the precision formula will grow larger.